目标
[掌握]- 现代C++核心的语言特性及使用场景[掌握]- 通过编译器报错信息定位问题的能力[熟悉]- 通过文档和cppreference解决C++中不熟悉问题的能力[了解]- 如何参与技术社区 - 开源项目的使用、提问题、参与讨论或贡献
快速开始
在线代码练习
点击下面按钮 即可在云端自动完成配置, 并进入练习代码检测模式
![]()
搭建本地练习环境
尝试
Code -> Book -> Video -> X -> Code
点击查看xlings安装命令
Linux/MacOS
curl -fsSL https://d2learn.org/xlings-install.sh | bash
Windows - PowerShell
irm https://d2learn.org/xlings-install.ps1.txt | iex
注: xlings工具 -> 详情
xlings install d2x:mcpp-standard
cd mcpp-standard
d2x checker
👉 更多细节...
社区
- 即时交流: 167535744、1067245099
- 论坛版块: 问题反馈、练习代码、技术交流和讨论
- 社区活动: 📣 MSCP - mcpp项目学习与贡献者培养计划
注: 复杂性问题(技术、环境搭建等问题)推荐在论坛发帖, 并详细描述问题细节, 能更有效于问题的解决和复用
参与贡献
- 参与社区交流: 反馈问题、参与社区问题讨论、帮助社区新用户解决问题
- 参与项目维护和开发: 参与社区中问题处理、修复Bug、多语言支持、加入MSCP活动小组、开发&优化新功能/模块
📑开源协议与贡献许可(License & CLA)
- 本项目欢迎自由使用与分发!你可以在 Apache License 2.0 和 CC-BY-NC-SA 4.0 协议下免费使用、修改和分享本项目的代码与文档内容
- 如希望参与贡献代码或文档,请先阅读贡献者许可协议(CLA)
👥贡献者

序言
mcpp-standard是一个开源、强调代码实践的现代C++核心语言特性教程项目。项目的总体结构为[Book + Video + Code + X]。为使用者提供了 在线电子书、对应的讲解视频、配套练习代码, 同时也提供了用于讨论交流的论坛和定期的学习活动...
语言支持
活动 | 📣 MSCP - mcpp项目学习与贡献者培养计划
MSCP是一款基于mcpp-standard开源项目开发的"地球Online"风格的角色扮演游戏。在游戏中你将扮演一个"编程初学者", 为了入门"现代C++"并揭露其背后的真相, 踏上了一条充满挑战和惊奇的现代C++学习之路...
价格:免费开发者:Sunrisepeak发行商:MOGA发行时间:2025年10月游戏体量:100H - 200H之间标签:类魂系列、模拟人生、🌍Online、程序员、C++、开源、费曼学习法- -> 游戏详情
使用说明
mcpp-standard是一个强调动手实践的现代C++核心语言特性教程项目。基于xlings(d2x)工具搭建了一套编译器驱动开发模式的代码练习, 可以自动化的检测练习代码的状态和跳转到下一个练习...
0.xlings工具安装
xlings包含教程项目所需的工具 - 更多工具细节
Linux
curl -fsSL https://d2learn.org/xlings-install.sh | bash
or
wget https://d2learn.org/xlings-install.sh -O - | bash
Windows - PowerShell
Invoke-Expression (Invoke-Webrequest 'https://d2learn.org/xlings-install.ps1.txt' -UseBasicParsing).Content
1.获取项目及自动配置环境
下载项目到当前目录并自动配置本地环境
xlings install d2x:mcpp-standard
本地电子书
可以在项目目录执行
d2x book命令, 打开本地文档(包含使用说明和电子书)
d2x book
练习代码自动检测
进入项目目录
mcpp-standard运行checker命令, 进入练习代码自动检测程序
d2x checker
指定练习进行检测
d2x checker [name]
注: 练习名支持模糊匹配
同步最新的练习代码
由于项目处于持续更新阶段, 可以使用下面的命令进行自动同步(如果同步失败, 可能需要手动用git进行更新项目代码)
d2x update
2.自动化检测程序简介
使用d2x checker进入自动化代码练习环境后, 工具会自动定位打开对应的练习代码文件, 并在控制台输出提示编译器的错误及提示信息。一般检测程序分两个检测阶段: 第一个是编译期检测, 即你需要通过练习代码中的提示信息和控制台编译器的报错, 修复代码的编译错误; 第二个是运行时检测, 即当前代码运行时是否能通过所有检查点。当修复编译错误并通过所有检查点时, 控制台就会显示当前练习通过并提示你进入下一个练习
代码练习文件示例
// mcpp-standard: https://github.com/Sunrisepeak/mcpp-standard
// license: Apache-2.0
// file: dslings/hello-mcpp.cpp
//
// Exercise/练习: 自动化代码练习使用教学
//
// Tips/提示:
// 该项目是使用xlings工具搭建的自动化代码练习项目, 通过在项目根目录下
// 执行 xlings checker 进入"编译器驱动开发模式"的练习代码自动检测.
// 你需要根据控制台的报错和提示信息, 修改代码中的错误. 当修复所有编译错误和
// 运行时检查点后, 你可以删除或注释掉代码中的 D2X_WAIT 宏, 会自动进入下一个练习.
//
// - D2X_WAIT: 该宏用于隔离不同练习, 你可以删除或注释掉该宏, 进入下一个练习.
// - d2x_assert_eq: 该宏用于运行时检查点, 你需要修复代码中的错误, 使得所有
// - D2X_YOUR_ANSWER: 该宏用于提示你需要修改的代码, 一般用于代码填空(即用正确的代码替换这个宏)
//
// Auto-Checker/自动检测命令:
//
// d2x checker hello-mcpp
//
#include <d2x/common.hpp>
// 修改代码时可以观察到控制台"实时"的变化
int main() {
std::cout << "hello, mcpp!" << std:endl; // 0.修复这个编译错误
int a = 1.1; // 1.修复这个运行时错误, 修改int为double, 通过检查
d2x_assert_eq(a, 1.1); // 2.运行时检查点, 需要修复代码通过所有检查点(不能直接删除检查点代码)
D2X_YOUR_ANSWER b = a; // 3.修复这个编译错误, 给b一个合适的类型
d2x_assert_eq(b, 1); // 4.运行时检查点2
D2X_WAIT // 5.删除或注释掉这个宏, 进入下一个练习(项目正式代码练习)
return 0;
}
控制台输出及解释
🌏Progress: [>----------] 0/10 -->> 显示当前的练习进度
[Target: 00-0-hello-mcpp] - normal -->> 当前的练习名
❌ Error: Compilation/Running failed for dslings/hello-mcpp.cpp -->> 显示检测状态
The code exist some error!
---------C-Output--------- - 编译器输出信息
[HONLY LOGW]: main: dslings/hello-mcpp.cpp:24 - ❌ | a == 1.1 (1 == 1.100000) -->> 错误提示及位置(24行)
[HONLY LOGW]: main: dslings/hello-mcpp.cpp:26 - 🥳 Delete the D2X_WAIT to continue...
AI-Tips-Config: https://d2learn.org/docs/xlings -->> AI提示(需要配置大模型的key, 可不使用)
---------E-Files---------
dslings/hello-mcpp.cpp -->> 当前检测的文件
-------------------------
Homepage: https://github.com/d2learn/xlings
3.配置项目(可选)
配置语言
编辑项目配置文件config.xlings中的lang属性, zh对应中文, en对应英文
},
private = {
-- project private attributes
mcpp = {
lang = "en", -- option: en, zh
}
},
}
自定义编辑器 - 以nvim编辑器为例
如果你希望使用 Neovim 编辑器并获得 LSP(clangd)支持, 可以按如下步骤进行配置
1.编辑项目配置文件config.xlings中的editor属性, 设置为nvim (或zed)
d2x = {
checker = {
name = "dslings",
editor = "nvim", -- option: vscode, nvim, zed
},
2.在项目根目录运行一键依赖安装和环境配置命令
xlings install
3.在项目目录, 重新运行检测命令 d2x checker 就会使用nvim打开对应练习文件, 并具备练习自动跳转/切换功能
注: nvim编辑器下的"实时检测功能"的触发时机, 将会对应到
:w命令. 即修改代码后, 在nvim的命令行模式对文件进行保存(:w)时, d2x就会更新检测结果
4.资源于交流
交流群(Q): 167535744
教程讨论版块: https://forum.d2learn.org/category/20
xlings: https://github.com/d2learn/xlings
教程仓库: https://github.com/Sunrisepeak/mcpp-standard
教程视频合集: https://space.bilibili.com/65858958/lists/5208246
类型自动推导 - auto和decltype
auto 和 decltype 是C++11引入的强有力的类型自动推导工具. 不仅让代码变的更加简洁, 还增强了模板和泛型的表达能力
| Book | Video | Code | X |
|---|---|---|---|
| cppreference-auto / cppreference-decltype / markdown | 视频解读 | 练习代码 |
为什么引入?
- 解决类型声明过于复杂的问题
- 模板应用中, 获取对象或表达式类型的需求
- 为lambda表达式的定义做支撑
auto和decltype有什么区别?
- auto常常用于变量定义, 推导的类型可能丢失const或引用(可显示指定进行保留auto &)
- decltype获取表达式的精确类型
- auto通常无法作为模板类型参数使用
一、基础用法和场景
声明定义
充当类型站位符, 辅助变量的定义或声明。使用auto时变量必须要初始化, decltype可以不用初始化
int b = 2;
auto b1 = b;
decltype(b) b2 = b;
decltype(b) b3; // 可以不用初始化
表达式类型推导
常常用于复杂表达式的类型推导, 确保计算精度
int a = 1;
auto b1 = a + 2;
decltype(a + 2 + 1.1) b2 = a + 2 + 1.1;
auto c1 = a + '0';
decltype(2 + 'a') c2 = 2 + 'a';
复杂类型推导
迭代器类型推导
std::vector<int> v = {1, 2, 3};
auto it = v.begin(); // 自动推导it类型
// decltype(v.begin()) it = v.begin();
for (; it != v.end(); ++it) {
std::cout << *it << " ";
}
函数类型推导
对于函数或lambda表达式这种复杂类型, 常常使用auto和decltype. 一般, lambda定义用auto, 模板类型参数用decltype
int add_func(int a, int b) {
return a + b;
}
int main() {
auto minus_func = [](int a, int b) { return a - b; };
std::vector<std::function<decltype(add_func)>> funcVec = {
add_func,
minus_func
};
funcVec[0](1, 2);
funcVec[1](1, 2);
//...
}
函数返回值类型推导
语法糖用法
auto为后置返回类型函数定义写法做支持, 并可以配合decltype进行返回类型推导使用
auto main() -> int {
return 0;
}
auto add(int a, double b) -> decltype(a + b) {
return a + b;
}
函数模板返回值类型推导
当无法确定模板返回值时可以用auto + decltype做推导, 可以让add支持一般类型int, double,... 和 复杂类型 Point, Vec,... 增强泛型的表达能力. (c++14中可以省略decltype)
template<typename T1, typename T2>
auto add(T1 a, T2 b) -> decltype(a + b) {
return a + b;
}
类/结构体成员类型推导
struct Object {
const int a;
double b;
Object() : a(1), b(2.0) { }
};
int main() {
const Object obj;
auto a = obj.a;
std::vector<decltype(obj.b)> vec;
}
二、注意事项 - 括号带来的影响
decltype(obj) 和 decltype( (obj) )的区别
- 一般
decltype(obj)获取的时其声明类型 - 而
decltype( (obj) )获取的是(obj)这个表达式的类型(左值表达式)
int a = 1;
decltype(a) b; // 推导结果为a的声明类型int
decltype( (a) ) c; // 推导结果为(a)这个左值表达式的类型 int &
decltype(obj.b) 和 decltype( (obj.b) )的区别
decltype( (obj.b) ): 从表达式视角做类型推导, obj定义类型会影响推导结果. 例如, 如果obj被const修饰时, const会限定obj.b的访问为constdecltype(obj.b): 由于推导的是成员声明类型, 所以不会受obj定义的影响
struct Object {
const int a;
double b;
Object() : a(1), b(2.0) { }
};
int main() {
Object obj;
const Object obj1;
decltype(obj.b) // double
decltype(obj1.b) // double
decltype( (obj.b) ) // double &
decltype( (obj1.b) ) // 受obj1定义的const修饰影响, 所以是 const double &
}
右值引用变量, 在表达式中是左值
int &&b = 1;
decltype(b) // 推导结果是声明类型 int &&
decltype( (b) ) // 推导结果是 int &
三、其他
...
列表初始化
列表初始是一种用{ arg1, arg2, ... }列表(大括号), 初始化对象的一种初始化风格, 并且可以用于几乎所有的对象初始化场景, 所以也常常称他为统一初始化。此外, 他还增加了列表成员的类型检查功能, 防止一些窄化问题
| Book | Video | Code | X |
|---|---|---|---|
| cppreference / markdown | 视频解读 | 练习代码 |
为什么引入?
- 解决初始化语法风格不统一问题
- 禁止隐式转换造成的窄化问题
- 方便容器类型的初始化
- 解决默认初始化语法陷阱
一、基础用法和场景
统一初始化风格
c++11之前不同场景有不同的初始化的方式
int a = 5; // 拷贝初始化
int b(5); // 直接初始化
int arr[3] = {1, 2, 3}; // 数组初始化
Object obj1; // 默认构造
Object obj2(obj1); // 拷贝构造
他们可以用{ }进行风格统一
int a = { 5 }; // 拷贝初始化
int b { 5 }; // 直接初始化
int arr[3] = {1, 2, 3}; // 数组初始化
Object obj1 { }; // 默认初始化
Object obj2 { obj1 }; // 拷贝构造
避免隐式类型转换和窄化问题
一般传统的初始化方法, 是默认C语言隐式类型转换规则风格. 例如, 用double类型初始化int类型变量的时候会自动丢掉小数位. 而列表初始化会增加额外的编译期类型检查来避免隐式类型转换和精度丢失问题. 在现代C++中, 除非有意的需要这种隐式类型转换, 大多数时候使用列表初始化是更好的选择
int a = 3.3; // ok
int a = { 3.3 }; // error
constexpr double b { 3.3 }; // ok
int c(b); // ok -> 3
int c { b }; // error: 类型不匹配
数组初始化中的窄化检查
int arr[] { 1, 2, 3.3, 4 }; // error: 3.3会发生窄化
int arr[] = { 1, 2, b, 4 }; // error: b会发生窄化
注: 如果b是运行时变量, 编译期可能只会触发窄化警告而不会报错
提高容器初始化的简洁性
对于容器类型的初始化, 老C++中常常会分成两个步骤。第一步, 创建一个元素数组; 第二步, 使用这个数组来初始化容器
int arr[5] = {1, 2, 3, 4, 5};
std::vector<int> v(arr, arr + sizeof(arr) / sizeof(int));
而列表初始化的引入, 能让我们把两步合为一个步骤, 大幅度提高了容器初始化的简洁性
std::vector<int> v1 {1, 2, 3};
std::vector<int> v2 {1, 2, 3, 4, 3};
并且, 可以通过std::initializer_list让我们的自定义类型也能支持这种不定长的列表初始化方式
class MyVector {
public:
MyVector() = default;
MyVector(std::initializer_list<int> list) {
for (auto it = list.begin(); it != list.end(); it++) {
// *it ...
}
}
};
MyVector v1 {1, 2, 3};
MyVector v2 {1, 2, 3, 4, 3};
避免初始化语法陷阱
使用{ }调用默认构造函数, 避免语法陷阱
#include <iostream>
struct Object {
Object() { std::cout << "Constructor called!" << std::endl; }
};
int main() {
Object obj1 { };
Object obj2(); // obj2是函数, 而不是Object对象
}
二、注意事项
数组类型列表初始化
数组类型的定义里面的值一般是不确定的, 但是列表初始化的方式会做默认值的初始化, 并支持自动补0
普通数组
int arr[4]; // arr[0] 不确定
int arr[4] { }; // arr[0] = 0
int arr[4] { 1, 2 }; // arr[2] / arr[3] 会自动补成0
数组容器
std::array<int, 4> arr; // arr[0] 不确定/可能是随机值
std::array<int, 4> arr { }; // arr[0] == 0
std::array<int, 4> arr { 1, 2 }; // arr[0] == 1, arr[2] 会自动补成0
成员初始化问题
列表初始化支持直接对 聚合类型的成员做初始化, 但需要注意添加构造函数后必须要匹配构造函数才可以
struct Point {
int x, y;
// Point(int x, int y) { ... }
};
Point { 1, 2 };
Point p1 { 2, 3 }; // p1 { x: 2, y: 3}
优先匹配std::initializer_list的构造函数
class MyVector {
public:
MyVector() = default;
MyVector(int x, int y) { }
MyVector(std::initializer_list<int> list) {
for (auto it = list.begin(); it != list.end(); it++) {
// *it ...
}
}
};
MyVector v1 { 1, 2 }; // 会优先匹配 MyVector(std::initializer_list<int> list)
MyVector v1(1, 2); // 匹配MyVector(int x, int y)
三、其他
委托构造函数
委托构造是C++11中引入的语法糖, 通过简单的语法, 可以在不影响性能的情况下, 来避免过多重复代码的编写, 实现构造逻辑复用
| Book | Video | Code | X |
|---|---|---|---|
| cppreference / markdown | 视频解读 | 练习代码 |
为什么引入?
- 构造函数重载中, 避免重复代码的编写
- 方便代码的维护
一、基础用法和场景
复用构造逻辑
当一个类需要编写重载的构造函数时, 很容易造成大量的重复代码, 例如:
class Account {
string id;
string name;
string coin;
public:
Account(string id_) {
id = id_;
name = "momo";
coin = "0元";
}
Account(string id_, string name_) {
id = id_;
name = name_;
coin = "0元";
}
Account(string id_, string name_, int coin_) {
id = id_;
name = name_;
coin = std::to_string(coin_) + "元";
}
};
这里3个构造函数中的初始化代码, 很明显是重复了(实际的初始化可能要更复杂)。 有了委托构造的支持后, 通过在构造函数成员初始化列表的位置以: Account(xxx)的形式来委托其他更加完整实现的构造函数进行构造, 这样就可以只保留一份代码
class Account {
string id;
string name;
string coin;
public:
Account(string id_) : Account(id_, "momo") { }
Account(string id_, string name_) : Account(id_, name_, 0) { }
Account(string id_, string name_, int coin_) {
id = id_;
name = name_;
coin = std::to_string(coin_) + "元";
}
};
上面的两个构造函数, 通过委托构造的方式, 最后都会转发到Account(string id_, string name_, int coin_)
为什么更方便维护?
可以假设, 如果上面货币的单位或名称需要修改时, 重复的代码实现不仅没有遵循复用原则, 而且修改构造逻辑时也要重复多次的修改, 提高了维护成本
而通过委托构造的方式, 把构造逻辑放到了一个地方, 这样修改和维护时也变的更加方便
例如, 我们需要把元改成原石时, 只要修改一次即可
class Account {
// ...
Account(string id_, string name_, int coin_) {
//...
//coin = std::to_string(coin_) + "元";
coin = std::to_string(coin_) + "原石";
}
};
和封装成一个init函数的区别
一些朋友可能会想到, 如果把构造逻辑写成一个init函数, 不就是也可以实现代码复用的效果吗? 为什么还要搞一个新的写法, 作为特性添加到标准中. 是不是有点多余并且让C++变的更加复杂了
class Account {
// ...
init(string id_, string name_, int coin_) {
id = id_;
name = name_;
coin = std::to_string(coin_) + "元";
}
public:
Account(string id_) { init(id_, "momo", 0); }
Account(string id_, string name_) { init(id_, name_, 0); }
Account(string id_, string name_, int coin_) {
init(id_, name_, coin_);
}
};
实际, 从性能角度考虑。大多数时候, 单独封装一个init函数的性能是低于委托构造的。因为成员的构造, 一般会经历两个阶段:
- 第一步: 执行 默认初始化 或 成员初始化列表
- 第二步: 运行构造函数体中的构造逻辑
class Account {
// ...
public:
Account(string id_, string name_, int coin_)
/* : 1 - 成员初始化列表 */
{
// 2 - 执行构造函数的函数体
init(id_, name_, coin_);
}
};
这就导致使用init函数, 实际上成员被"初始化"了两次, 而委托构造可以通过成员初始化列表来避免这个问题
class Account {
// ...
public:
Account(string id_, string name_, int coin_)
: id { id_ }, name { name_ }, coin { std::to_string(coin_) + "元" }
{
// ...
}
};
二、注意事项
临时对象误会
在一些不使用委托构造的场景中, 一个构造函数体中调用另外一个构造函数, 他实际只是创建了一个临时对象
- 调用普通函数
init: 初始化的是本对象的成员 - 调用另外一个构造函数: 在本对象外, 创建了一个新的临时对象
class Account {
// ...
public:
Account(string id_, string name_) {
Account(id_, name_, 0); // 创建的是临时对象
// init(id_, name_, 0);
// this->Account(id_, name_, 0); // error
}
Account(string id_, string name_, int coin_) {
id = id_;
name = name_;
coin = std::to_string(coin_) + "元";
}
};
不能重复初始化
当使用委托构造时, 就不能使用初始化列表去初始化其他成员, 这样的限制可以避免重复的初始化, 保证了数据成员只会被初始化一次
例如, 如果下面的语法被允许 coin 将会被初始化多次且可能会造成歧义
class Account {
// ...
public:
Account(string id_)
: Account(id_, "momo"), coin { "0元" } // error
{
}
};
三、其他
继承构造函数
继承构造函数是C++11 引入的一个语法特性 - 解决了在类继承结构中 派生类重复定义基类构造函数 的繁琐问题
| Book | Video | Code | X |
|---|---|---|---|
| cppreference / markdown | Bili / Youtube | 练习代码 |
为什么引入?
- 减少重复代码, 避免手动转发
- 提高代码的表达能力
一、基础用法和场景
复用基类的构造函数
在继承构造函数这个特性引入之前, 即使基类和派生的构造函数形式没有任何区别, 也需要重新定义, 这不仅造成了一定程度的代码重复, 而且也不够简洁。例如, 下面的MyObject就对每个Base中的构造函数做了重新实现
class ObjectBase {
//...
public:
ObjectBase(int) {}
ObjectBase(double) {}
};
class MyObject : public ObjectBase {
public:
MyObject(int x) : ObjectBase(x) {}
MyObject(double y) : ObjectBase(y) {}
//...
};
而用这个特性, 可以通过using ObjectBase::ObjectBase;直接继承基类中的构造函数, 避免这个手动转发的过程
class MyObject : public ObjectBase {
public:
using ObjectBase::ObjectBase;
//...
};
这里需要注意的是, 构造函数继承 的编译期隐式代码生成, 不仅仅是对构造函数的"单纯"复制, 而且在派生类中还有类似"自动重命名的效果 ObjectBase -> MyObject "。即:
class MyObject : public ObjectBase {
public:
// 可能的生成代码
MyObject(int x) : ObjectBase(x) {}
MyObject(double y) : ObjectBase(y) {}
};
类型的功能扩展
在很多特殊的场景下, 我们可能只想给某个类型追加额外的行为/方法, 而不改变其构造行为。这个时候就可使用继承构造
class ObjectXXX : public Object {
public:
using Object::Object;
void your_method() { /* ... */ }
};
对一些类型做测试或调试时, 我们常常期望可以使用像to_string()之类的一些接口。如果在不方便直接修改源代码的情况下, 就可以使用 继承构造函数 的性质创建一个"具有一样接口"的新类型, 并追加一些方便调试的接口函数, 从而在有更方便的调试函数下实现间接测试。例如下面有个Student类:
class Student {
protected:
//...
double score;
public:
string id;
string name;
uint age;
Student(string id, string name);
Student(string id, string name, uint age);
Student(string id, ...);
};
通过实现StudentDebug并增加一些辅助函数, 这样更方便来获取调试信息
class StudentDebug : public Student {
public:
using Student::Student;
std::string to_string() const {
return "{ id: " + id + ", name: " + name
+ ", age: " + std::to_string(age) + " }";
}
void dump() const { /* 一些成绩细节 ... */ }
void assert_valid() const {
assert(score >= 0 && score <= 100);
// ...
}
};
同时, 在使用StudentDebug的时候, 不管是对象的创建还有原方法的使用都和Student保持了一致。所以对于这种 只是增加行为, 而不改变原类型对象的构造形式的需求, 使用继承构造能很大程度的简化代码
注: 一般这种方式可以保持同基类一样的 对象构造 + 行为/方法调用形式。但并不一定有一样的内存布局(例如新增虚方法), 并且类型判断上(RTTI)是不相等的
异常或错误类型标识和转发
在错误和异常处理时, 我们可以只定义一个基础的错误类型
class ErrorBase {
public:
ErrorBase() { }
ErrorBase(const char *) { }
ErrorBase(std::string) { }
//...
};
在定义多个标识场景的错误类型时, 通过使用继承构造函数, 可以轻松的让他们保持和基础错误类型一样的构造形式。例如:
class ConfigError : public ErrorBase {
public:
using ErrorBase::ErrorBase;
};
class RuntimeError : public ErrorBase {
public:
using ErrorBase::ErrorBase;
};
class IoError : public ErrorBase {
public:
using ErrorBase::ErrorBase;
};
每个场景的错误, 对应一个错误类型, 不仅保持了错误对象构造的统一, 也非常适合配合C++的重载机制做错误类型的自动转发和处理。例如, 我们可以给每个错误类型实现对应的处理函数, 没有实现的类型将会使用基础类型对应的处理函数, 非常像很多编程语言中异常捕获和处理的设计。例如下面自定义的错误处理器:
struct MyErrProcessor {
static void process(ErrorBase err) { /* 基础处理 */ }
static void process(ConfigError err) { /* 配置错误处理 */ }
// ...
};
MyErrProcessor::process(errObj); // 自动匹配对应的错误处理函数
泛型装饰器和行为约束
继承构造函数不仅可以用于普通的继承中, 他还可以用于模板类型。例如, 下面定义的NoCopy中, 使用了using T::T对泛型T中的构造函数做继承。他的作用是在不改变目标对象的构造形式和使用接口下, 做一定的行为约束
template <typename T>
class NoCopy : public T {
public:
using T::T;
NoCopy(const NoCopy&) = delete;
NoCopy& operator=(const NoCopy&) = delete;
// ...
};
在一些模块或场景中, 我们期望再对象创想创建后, 不能再复制的方式创建其他对象时, 就可以在定义时使用这个NoCopy装饰器/包装器, 通过包装器中的delete显示告诉编译器删除了拷贝构造和拷贝赋值, 也意味着对象不在拥有拷贝语义。例如:
class Point {
double mX, mY;
public:
Point() : mX { 0 }, mY { 0 } { }
Point(double x, double y) : mX { x }, mY { y } { }
string to_string() const {
return "{ " + std::to_string(mX)
+ ", " + std::to_string(mY) + " }";
}
};
Point p1(1, 2);
NoCopy<Point> p2(2, 3);
这个时候p1和p2在接口的使用上都是一样的, 但是p2相对p1就少了可拷贝的属性
p1.to_string(); // ok
p2.to_string(); // ok
auto p3 = p1; // ok (拷贝构造)
auto p4 = p2; // error (不能拷贝)
二、注意事项
优先考虑继承还是组合
由于本章是介绍继承构造函数的特性和使用方式, 它是和继承性质绑定的。所以, 从实现上是倾向用继承的方式来实现的。 但是从于目标功能上考虑, 往往使用继承和组合都是可以实现的, 他们更偏向是手段而不是目的, 所以选择需要结合具体的应用场景。
例如, 对于一些测试环境, 或仅功能函数扩展, 无数据结构变动的场景下, 使用继承配合继承构造函数是比较方便的, 还可以避免大量的函数转发。但是, 对于一些 要对少量特定接口做"拦截"或较复杂的场景, 现在(2025)主流是更倾向用组合代替继承的
- 复杂场景或要加一个中间层做特殊处理 -> 一般组合优于继承
- 简单功能扩展, 且需保留接口使用的一致 -> 一般继承优于组合
三、练习代码
练习代码主题
练习代码自动检测命令
d2x checker inherited-constructors
四、其他
nullptr - 指针字面量
nullptr 是C++11引入的指针字面量,用于表示空指针。它解决了传统空指针表示方式(如NULL和0)在类型安全性和重载解析方面的不足。
| Book | Video | Code | X |
|---|---|---|---|
| cppreference / markdown | 视频解读 | 练习代码 |
为什么引入?
- 解决
NULL宏和整数0在重载解析中的歧义问题 - 提供类型安全的空指针表示方式
- 明确区分指针和整数类型
- 支持模板编程中的类型推导
nullptr和NULL有什么区别?
nullptr是C++11引入的关键字,类型为std::nullptr_tNULL是预处理宏,通常定义为整数0或(void*)0nullptr在重载解析中更精确,不会与整数类型混淆
一、基础用法和场景
替代NULL和0
用于指针变量的初始化和赋值,替代传统的
NULL和0
int* ptr1 = nullptr; // 推荐用法
int* ptr2 = NULL; // 传统用法
int* ptr3 = 0; // 不推荐
// 检查指针是否为空
if (ptr1 == nullptr) {
// 处理空指针情况
}
解决重载歧义问题
在函数调用中明确传递空指针,
nulltpr能避免重载歧义问题, 并且避免与整数类型的混淆
void func(int* ptr) {
if (ptr != nullptr) {
*ptr = 42;
}
}
void func(int value) {
// 处理整数参数
}
int main() {
func(nullptr); // 明确调用指针版本
func(0); // 可能调用整数版本,产生歧义
func(NULL); // 可能调用整数版本,产生歧义
}
例如上面的代码中,调用func(NULL)就会报重载歧义错误
main.cpp: In function 'int main()':
main.cpp:16:9: error: call of overloaded 'func(NULL)' is ambiguous
16 | func(NULL); // 可能调用整数版本,产生歧义
| ~~~~^~~~~~
确保模板编程中的类型安全
在模板函数和类中,
nullptr提供更好的类型推导和安全性
// https://en.cppreference.com/w/cpp/language/nullptr.html
template<class T>
constexpr T clone(const T& t) {
return t;
}
void g(int*) {
std::cout << "Function g called\n";
}
int main() {
g(nullptr); // ok
g(NULL); // ok
g(0); // ok
g(clone(nullptr)); // ok
g(clone(NULL)); // ERROR: NULL可能会被推导成非"指针"类型
g(clone(0)); // ERROR: 0会被推导成非"指针"类型
}
当使用函数模板时, NULL和0通过会被推导成非"指针"类型, 而nullptr可以避免这个问题
main.cpp:19:12: error: invalid conversion from 'int' to 'int*' [-fpermissive]
19 | g(clone(0)); // ERROR: 0会被推导成非"指针"类型
| ~~~~~^~~
| |
| int
智能指针和容器
与现代C++特性(如智能指针、STL容器)配合使用
#include <memory>
#include <vector>
int main() {
std::shared_ptr<int> sp1 = nullptr;
std::unique_ptr<int> up1 = nullptr;
std::vector<int*> vec;
vec.push_back(nullptr);
// 检查智能指针是否为空
if (sp1 == nullptr) {
sp1 = std::make_shared<int>(42);
}
}
二、注意事项
类型推导和std::nullptr_t
nullptr的类型是std::nullptr_t,这是一个特殊的类型,可以 隐式 转换为任何指针类型:
#include <cstddef> // 包含std::nullptr_t的定义
void func(int*) {}
void func(double*) {}
void func(std::nullptr_t) {}
int main() {
auto ptr = nullptr; // ptr的类型是std::nullptr_t
func(nullptr); // 调用std::nullptr_t版本
func(ptr); // 调用std::nullptr_t版本
int* intPtr = nullptr;
func(intPtr); // 调用int*版本
}
与布尔类型的隐式转换
nullptr可以隐式转换为bool类型,在条件判断中非常方便:
int* ptr = nullptr;
if (ptr) { // 等价于 if (ptr != nullptr)
// 指针非空
} else {
// 指针为空
}
bool isEmpty = (ptr == nullptr); // true
三、练习代码
练习代码主题
- 0 - nullptr基础用法
- 1 - nullptr的函数重载
- 2 - nullptr在模板编程中的优势
练习代码自动检测命令
d2x checker nullptr
四、其他
long long - 64位整数类型
long long 是C++11引入的64位整数类型,用于表示更大范围的整数值。它解决了传统整数类型在表示大整数时的范围限制问题。
| Book | Video | Code | X |
|---|---|---|---|
| cppreference / markdown | 视频解读 | 练习代码 |
为什么引入?
- 解决传统整数类型范围不足的问题
- 提供统一的64位整数类型标准
long long和传统整数类型有什么区别?
long long保证至少64位宽度,范围至少为 -2^63 到 2^63-1int通常为32位,范围约为 -21亿到21亿long在32位系统上为32位,在64位系统上通常为64位(但标准只保证至少32位)
一、基础用法和场景
基本声明和初始化
支持有符号和无符号, 以及字面量后缀标识
// 有符号long long
long long val1 = 1;
long long val2 = -1;
// 无符号long long
unsigned long long uVal1 = 1;
// 字面量标识 + 类型推导
auto longlong = 1LL:
auto ulonglong = 1ULL;
大整数应用和边界值
处理超出传统整数类型范围的计算,基于边界值获取
//#include <limits>
// 使用long long处理大数计算(超过int表示范围)
long long population = 7800000000LL; // 世界人口
// 获取整数类型边界
int maxInt = std::numeric_limits<int>::max();
long long maxLL = std::numeric_limits<long long>::max();
auto minLL = std::numeric_limits<long long>::min();
二、注意事项
类型推导和字面量后缀
使用LL或ll后缀明确指定long long字面量,使用ULL或ull指定无符号版本
auto num1 = 10000000000; // 类型可能是int或long,取决于编译器
auto num2 = 10000000000LL; // 明确为long long辅助类型推导
类型转换和精度问题
注意不同整数类型之间的转换可能导致的精度损失
long long bigValue = 3000000000LL;
int smallValue = bigValue; // 可能溢出
std::cout << "bigValue: " << bigValue << std::endl;
std::cout << "smallValue: " << smallValue << std::endl; // 可能不正确
// 安全转换检查
if (bigValue > std::numeric_limits<int>::max() || bigValue < std::numeric_limits<int>::min()) {
std::cout << "转换会导致溢出!" << std::endl;
}
位宽疑惑 - 标准中为什么不固定位宽?
原因
- 硬件差异问题: 不同架构“自然字长”不同:16/32/64 位都有,大量嵌入式甚至只有 8/16 位乘除指令.若强行规定(long为64位),一些机器(32 位 MCU)上会造成巨大的性能损失
- 例如: 在8位机器上做64位计算, 但没有相关的机器指令。所以需要通过算法模拟的方式实现, 进而导
指令周期攀升
- 例如: 在8位机器上做64位计算, 但没有相关的机器指令。所以需要通过算法模拟的方式实现, 进而导
- 历史与 ABI 兼容: C/C++ 起源早于现代 32/64 位普及,许多平台的系统接口、文件格式、调用约定都已把 int/long 的大小写进了 ABI。标准若强制改变,会破坏二进制兼容和生态
- 零成本抽象: C/C++ 标准面向“与机器高效映射”的抽象机,只规定行为与最小范围,让实现能选择对该平台最自然的宽度,从而获得零开销抽象或接近零开销
解决方案
- C/C++提供了可选方案: 需要精确位宽时,可以使用
<cstdint>/<stdint.h>里的int8_t、int16_t、int32_t、int64_t... - 不假设位宽和静态断言: 开发时不假设类型的位宽, 从而提高可移植性. 如果部分代码做了位宽假设, 可以通过静态断言来保证位宽符合预期
static_assert(sizeof(T)==N)
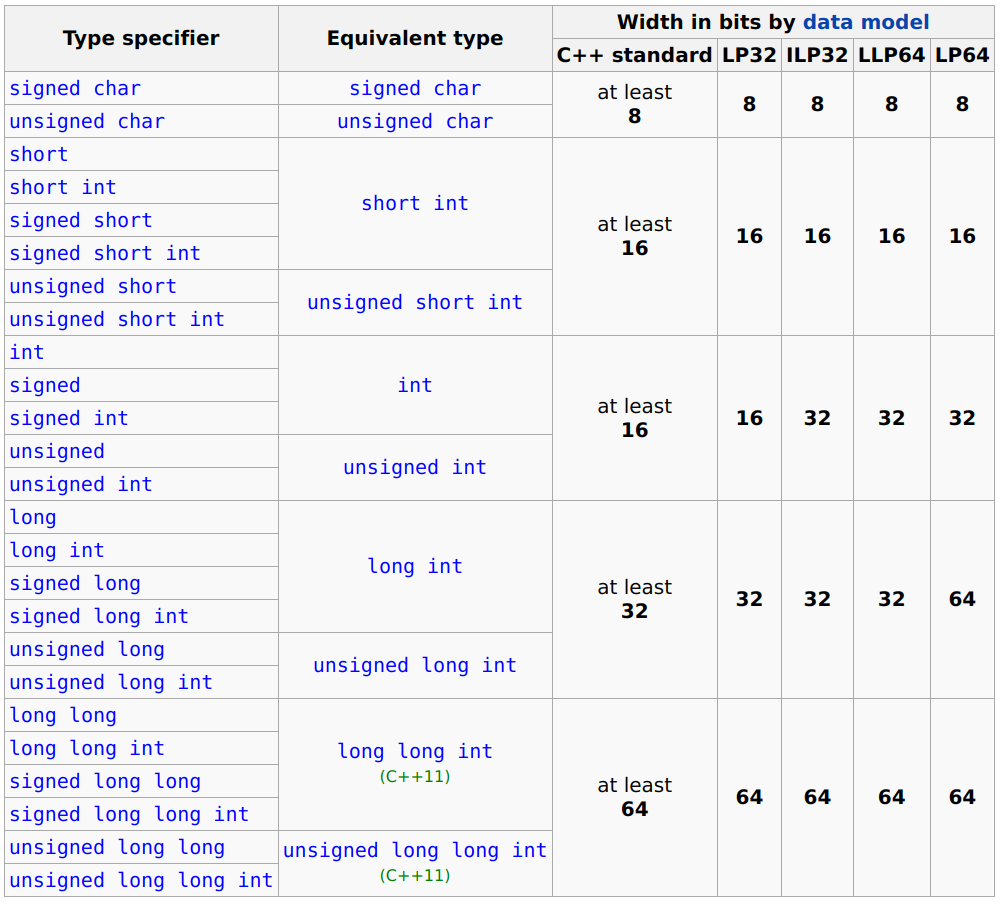
三、练习代码
练习代码主题
- 0 - long long基础用法
- 1 - long long大数应用和边界值
练习代码自动检测命令
d2x checker long-long
四、其他
类型别名和别名模板
类型别名和别名模板是C++11引入的重要特性,用于为现有类型创建新的名称,增强泛型编程的表达能力,提高代码的可读性和可维护性。
| Book | Video | Code | X |
|---|---|---|---|
| cppreference-type-alias / markdown | 视频解读 | 练习代码 |
注:
using关键字在C++11之前就已经存在, 但当时主要是作为命名空间和类成员声明来使用的
- 声明命名空间:
using namespace std;- 类成员声明:
struct B : A { using A::member; };
为什么引入?
- 替代传统的
typedef语法,提供更直观的类型别名定义方式 - 支持模板别名,增强泛型编程的表达能力
- 提高代码可读性,特别是对于复杂类型
- 与
using声明语法保持一致
类型别名和typedef有什么区别?
- 语法更直观:
using NewType = OldType;vstypedef OldType NewType; - 支持模板别名,而
typedef不支持 - 在模板编程中更加灵活和强大
一、基础用法和场景
基本类型别名
为现有类型创建新的名称,提高代码可读性, 并且可以取代传统
typedef定义别名的方式
typedef int Integer; // 传统typedef方式
using Integer = int; // C++11 using方式
// 使用别名
Integer i = 1;
int j = 2;
类型别名并不是一个新的类型, 而是其他复合类型的一个别名, 本质是一样的。像上的代码中Integer的本质就是int, 常用于简化类型名
复杂类型别名
为复杂类型(如函数指针、嵌套类型)创建别名
// 函数指针别名
using FuncPtr = void(*)(int, int);
using StringVector = std::vector<std::string>;
// 嵌套类型别名
struct Container {
using ValueType = int;
using Iterator = std::vector<ValueType>::iterator;
};
void example(int a, int b) {
// 函数实现
}
int main() {
FuncPtr func = example; // 等价: void(*func)(int, int) = example;
StringVector strings = {"hello", "world"}; // 等价: std::vector<std::string> strings...
Container::ValueType value = 100; // 等价: int value = 100;
return 0;
}
对于void (*func) (int, int) = example;这样的代码很多人看到可能都要迟疑一下才能反应过来, 它是定义了一个函数指针。通过使用using给个复杂类型起一个类型别名FuncPtr, 使用FuncPtr func = example;就能让人快速获取代码意图了
别名模板
为模板类型创建别名,增强泛型编程能力
// 别名模板
template <typename T>
using Vec = std::vector<T>;
// 基于泛型, 创建其"子集合"别名类型
template <typename T>
using Vec3 = std:Array<T, 3>;
template <typename T>
using Vec4 = std:Array<T, 4>;
// 带默认参数的别名模板
template <typename T, typename Compare = std::less<T>>
using Heap = std::priority_queue<T, std::vector<T>, Compare>;
int main() {
Vec<int> numbers = {1, 2, 3};
Vec3<float> v3 = {1.0f, 2.0f, 3.0f};
Vec4<float> v4 = {1.0f, 2.0f, 3.0f, 4.0f};
Heap<int> minHeap;
Heap<int, std::greater<int>> maxHeap;
return 0;
}
除了给复杂创建别名外, 还支持给模板类型创建别名, 并且通过模板参数还能实现对原模板类型的参数/属性进行控制 - 默认参数、分配器类型、长度、比较器等. 在上面的代码中我们分别创建了动态Vec类型别名; 也通过指定长度, 创建了定长的Vec3、Vec4服务于特殊场景(向量、矩阵计算)的类型别名; 还用模板参数默认指创建了Heap类型, 底层默认使用vector作为数据结构, 并支持默认最小堆, 和通过指定模板参数的方式设置最大堆
标准库中_t风格的模板
在STL中有一些模板, 会提供_t的版本, 来节省手动获取类型和取值的过程。使用类型别名可以轻松的实现他们(_v风格需要C++17的[inline variables + variable templates]的支持)
std:remove_const_t的参考实现
// remove_const的实现和原理解释可参考: https://zhuanlan.zhihu.com/p/352972564
template <typename T>
using my_remove_const_t = typename std::remove_const<T>::type;
int main() {
const int a = 10;
my_remove_const_t<decltype(a)> b = a; // b的类型为int,而不是const int
return 0;
}
二、注意事项
别名不是新类型
类型别名只是现有类型的同义词,不会创建新类型
using MyInt = int;
using YourInt = int;
int main() {
MyInt a = 10;
YourInt b = 20;
a = b; // 可以赋值,因为都是int类型
static_assert(std::is_same<MyInt, YourInt>::value, "Types are the same");
return 0;
}
模板别名的作用域
别名模板必须在类作用域或命名空间作用域中声明
namespace MyNamespace {
template<typename T>
using MyVector = std::vector<T>;
}
class MyClass {
public:
template<typename T>
using Ptr = T*;
};
// 错误:不能在函数作用域中声明别名模板
// void func() {
// template<typename T>
// using LocalAlias = T; // 编译错误
// }
递归别名限制
别名模板不能直接或间接引用自身
template<typename T>
struct A;
// 错误:递归别名
// template<typename T>
// using B = typename A<T>::U;
template<typename T>
struct A {
// typedef B<T> U; // 这会导致递归定义错误
};
三、练习代码
练习代码主题
- 0 - 基本类型别名
- 1 - 复杂类型和函数指针别名
- 2 - 别名模板基础
- 3 - 标准库中的别名模板应用
练习代码自动检测命令
d2x checker type-alias
四、其他
mcpp-standard更新日志
2025/11
C++11 - 13 - long long - 64位整数类型
C++11 - 12 - nullptr - 指针字面量
2025/09
C++11 - 11 - 继承构造造函数
2025/08
C++11 - 11 - 继承构造造函数
C++11 - 10 - 委托构造函数
练习检测命令
d2x checker delegating-constructors
常见问题
更多问题和反馈 -> 教程论坛交流版块